So, this has been rather a bane on the life which is lived as Adam Bull. Basically, a large customer of ours had 50+ CDN’s, and literally hundreds of gigabytes of Log Files. They were all in Rackspace Cloud Files, and the big question was ‘how do I know how busy my CDN is?’.
This is a remarkably good question, because actually, not many tools are provided here, and the customer will, much like on many other CDN services, have to download those logs, and then process them. But that is actually not easier either, and I spent a good few weeks (albeit when I had time), trying to figure out the best way to do this. I dabbled with using tree to display the most commonly used logs, I played with piwik, awstats, and many others such as goaccess, all to no avail, and even used a sophisticated AWK script from our good friends in Operations. No luck, nothing, do not pass go, or collect $200. So, I was actually forced to write something to try and achieve this, from start to finish. There are 3 problems.
1) how to easily obtain .CDN_ACCESS_LOGS from Rackspace Cloud Files to Cloud Server (or remote).
2) how to easily process these logs, in which format.
3) how to easily present these logs, using which application.
The first challenge was actually retrieving the files.
swiftly --verbose --eventlet --concurrency=100 get .CDN_ACCESS_LOGS --all-objects -o ./
Naturally to perform this step above, you will need a working, and setup swiftly environment. If you don’t know what swiftly, is or understand how to set up a swiftly envrionment, please see this article I wrote on the subject of deleting all files with swiftly (The howto explains the environment setup first! Just don’t follow the article to the end, and continue from here, once you’ve setup and installed swiftly)
Fore more info see:
https://community.rackspace.com/products/f/25/t/7190
Processing the Rackspace CDN Logs that we’ve downloaded, and organising them for further log processing
This required a lot more effort, and thought
The below script sits in the same folder as all of the containers
# ls -al
total 196
drwxrwxr-x 36 root root 4096 Nov 7 12:33 .
drwxr-xr-x 6 root root 4096 Nov 7 12:06 ..
# used by my script
-rw-rw-r-- 1 root root 1128 Nov 7 12:06 alldirs.txt
# CDN Log File containers as we downloaded them from swiftly Rackspace Cloud Files (.CDN_ACCESS_LOGS)
drwxrwxr-x 3 root root 4096 Oct 19 11:22 dev.demo.video.cdn..com
drwxrwxr-x 3 root root 4096 Oct 19 11:22 europe.assets.lon.tv
drwxrwxr-x 5 root root 4096 Oct 19 11:22 files.lon.cdn.lon.com
drwxrwxr-x 3 root root 4096 Oct 19 11:23 files.blah.cdn..com
drwxrwxr-x 5 root root 4096 Oct 19 11:24 files.demo.cdn..com
drwxrwxr-x 3 root root 4096 Oct 19 11:25 files.invesco.cdn..com
drwxrwxr-x 3 root root 4096 Oct 19 11:25 files.test.cdn..com
-rw-r--r-- 1 root root 561 Nov 7 12:02 generate-report.sh
-rwxr-xr-x 1 root root 1414 Nov 7 12:15 logparser.sh
# Used by my script
drwxr-xr-x 2 root root 4096 Nov 7 12:06 parsed
drwxr-xr-x 2 root root 4096 Nov 7 12:33 parsed-combined
#!/bin/bash
# Author : Adam Bull
# Title: Rackspace CDN Log Parser
# Date: November 7th 2016
echo "Deleting previous jobs"
rm -rf parsed;
rm -rf parsed-combined
ls -ld */ | awk '{print $9}' | grep -v parsed > alldirs.txt
# Create Location for Combined File Listing for CDN LOGS
mkdir parsed
# Create Location for combined CDN or ACCESS LOGS
mkdir parsed-combined
# This just builds a list of the CDN Access Logs
echo "Building list of Downloaded .CDN_ACCESS_LOG Files"
sleep 3
while read m; do
folder=$(echo "$m" | sed 's@/@@g')
echo $folder
echo "$m" | xargs -i find ./{} -type f -print > "parsed/$folder.log"
done < alldirs.txt
# This part cats the files and uses xargs to produce all the Log oiutput, before cut processing and redirecting to parsed-combined/$folder
echo "Combining .CDN_ACCESS_LOG Files for bulk processing and converting into NCSA format"
sleep 3
while read m; do
folder=$(echo "$m" | sed 's@/@@g')
cat "parsed/$folder.log" | xargs -i zcat {} | cut -d' ' -f1-10 > "parsed-combined/$folder"
done < alldirs.txt
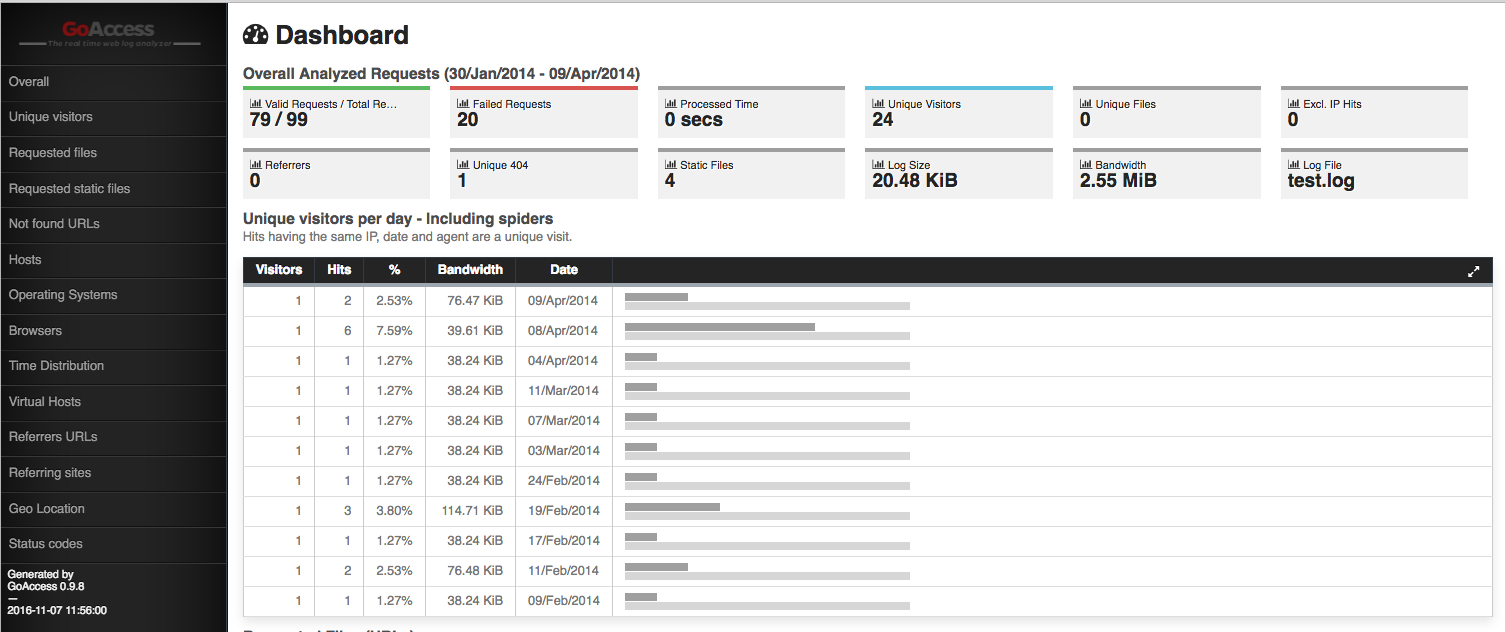
# This part processes the Log files with Goaccess, generating HTML reports
echo "Generating Goaccess HTML Logs"
sleep 3
while read m; do
folder=$(echo "$m" | sed 's@/@@g')
goaccess -f "parsed-combined/$folder" -a -o "/var/www/html/$folder.html"
done < alldirs.txt
How to easily present these logs
I kind of deceived you with the last step. Actually, because I have already done it, with the above script. Though, you will naturally need to have an httpd installed, and a documentroot in /var/www/html, so make sure you install apache2:
yum install httpd awstats
De de de de de de da! da da!
Some little caveats:
Generating a master index.html file of all the sites
[root@cdn-log-parser-mother html]# pwd
/var/www/html
[root@cdn-log-parser-mother html]# ls -al | awk '{print $9}' | xargs -i echo " {}
" > index.html
I will expand the script to generate this automatically soon, but for now, leaving like this due to time constraints.
